警告
本文最后更新于 2020-10-01,文中内容可能已过时。
查漏补缺的一些问题
定义与声明的区别(20200815)
这是一直都比较纠结的一些问题,记录在这里。
变量的声明有两种情况:
- 需要建立存储空间,这种称为定义性声明(defining declaration),简称定义
- 不需要建立存储空间,这种称为引用性声明(referncing declaration)
所以广义的讲,声明包含定义,定义是声明的一个特例。
在 Go 中,基本变量类型在声明时都会分配存储空间并分配默认值,因此都属于定义性声明
1
2
3
4
5
| var (
a int
b float32
c bool
)
|
但是,像切片、映射、通道等,声明时不会分配存储空间,要分配空间还必须使用 make 内置函数,因此它们是引用性声明
1
2
| var a []int
a = make([]int,3)
|
在 Go 的官方文档中,使用的也都是 declaration 这个词,统一用「声明」来描述
对自定义类型进行排序(20190816)
PAT乙级25分的题好多需要根据一个结构体类型的某个字段进行排序,第一次遇到时确实不知所措,然后查了不少解决方案,这里做个总结。
这一问题一般归结为对自定义类型排序,当然,基本指的是结构体,搜到的解决方案也基本是利用sort包。
sort包基本的排序都是针对切片的,直接调用的话能找到整型、浮点型和字符串三种类型切片的排序,最简单的整型排序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| package main
import (
"fmt"
"sort"
)
func main() {
s := []int{5, 2, 6, 3, 1, 4} // unsorted
sort.Ints(s)
fmt.Println(s)
}
//Output:[1 2 3 4 5 6]
|
调用sort.Sort()
不少文章都是通过调用sort.Sort()实现的对结构体的排序,如youyu岁月和Donne的文章就是使用的这种办法。
1
| func Sort(data Interface)
|
Sort函数会调用一次data.Len确定长度,调用O(n*log(n))次data.Less和data.Swap进行排序。但函数不能保证排序的稳定性。而调用Sort首先需要实现一个接口。
1
2
3
4
5
6
7
8
9
| type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less reports whether the element with
// index i should sort before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}
|
只要实现了Len, Less, Swap三个方法,就能调用Sort实现对结构体的排序,而其中主要就是Less比较逻辑的实现。
先看一下sort包本身对[]int类型的排序实现
1
2
3
4
5
6
7
8
9
10
11
| // 首先定义了一个[]int类型的别名IntSlice
type IntSlice []int
// 获取此 slice 的长度
func (p IntSlice) Len() int { return len(p) }
// 比较两个元素大小 升序
func (p IntSlice) Less(i, j int) bool { return p[i] < p[j] }
// 交换数据
func (p IntSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
// sort.Ints()内部调用Sort() 方法实现排序
// 注意 要先将[]int 转换为 IntSlice类型 因为此类型才实现了Interface的三个方法
func Ints(a []int) { Sort(IntSlice(a)) }
|
然后我们以一个人的结构体为例,结构体中包括其姓名和年龄,按照其年龄对结构体进行排序。
1
2
3
4
5
| type Person struct {
Name string
Age int
}
type ByAge []Person
|
仿照[]int实现三个方法
1
2
3
| func (a ByAge) Len() int { return len(a) }
func (a ByAge) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByAge) Less(i, j int) bool { return a[i].Age < a[j].Age }
|
然后写个完整的程序测试看一看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| package main
import (
"fmt"
"sort"
)
type Person struct {
Name string
Age int
}
func (p Person) String() string {
return fmt.Sprintf("%s: %d", p.Name, p.Age)
}
// ByAge implements sort.Interface for []Person based on
// the Age field.
type ByAge []Person
func (a ByAge) Len() int { return len(a) }
func (a ByAge) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByAge) Less(i, j int) bool { return a[i].Age < a[j].Age }
func main() {
people := []Person{
{"Bob", 31},
{"John", 42},
{"Michael", 17},
{"Jenny", 26},
}
fmt.Println(people)
// There are two ways to sort a slice. First, one can define
// a set of methods for the slice type, as with ByAge, and
// call sort.Sort. In this first example we use that technique.
sort.Sort(ByAge(people))
fmt.Println(people)
}
//输出结果如下:
[Bob: 31 John: 42 Michael: 17 Jenny: 26]
[Michael: 17 Jenny: 26 Bob: 31 John: 42]
|
如果要对某个结构体中多个字段进行排序,可以利用嵌套结构体实现,如下面的代码,该代码来自youyu岁月
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| package main
import (
"fmt"
"sort"
)
type Person struct {
Name string
Age int
}
type Persons []Person
// Len()方法和Swap()方法不用变化
// 获取此 slice 的长度
func (p Persons) Len() int { return len(p) }
// 交换数据
func (p Persons) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
// 嵌套结构体 将继承 Person 的所有属性和方法
// 所以相当于SortByName 也实现了 Len() 和 Swap() 方法
type SortByName struct{ Persons }
// 根据元素的姓名长度降序排序 (此处按照自己的业务逻辑写)
func (p SortByName) Less(i, j int) bool {
return len(p.Persons[i].Name) > len(p.Persons[j].Name)
}
type SortByAge struct{ Persons }
// 根据元素的年龄降序排序 (此处按照自己的业务逻辑写)
func (p SortByAge) Less(i, j int) bool {
return p.Persons[i].Age > p.Persons[j].Age
}
func main() {
persons := Persons{
{
Name: "test123",
Age: 20,
},
{
Name: "test1",
Age: 22,
},
{
Name: "test12",
Age: 21,
},
}
fmt.Println("排序前")
for _, person := range persons {
fmt.Println(person.Name, ":", person.Age)
}
sort.Sort(SortByName{persons})
fmt.Println("排序后")
for _, person := range persons {
fmt.Println(person.Name, ":", person.Age)
}
}
|
调用sort.Slice()
更简单的是直接调用sort.Slice(),当然,由于golang官方的包说明稳定没法访问,一直查看的是国内的标准库说明文档,完全没有意识到它已经落后了,可能许久未更新,完全没有提到sort包中的Slice函数,但利用这个函数进行自定义类型排序是真有用,还是翻出去看官方说明比较好。
1
| func Slice(slice interface{}, less func(i, j int) bool)
|
sort.Slice()以给定的比较函数排序切片,但并不保证排序的稳定性,想要稳定性,可以调用sort.SliceStable()。因为切片类型的广泛使用,调用sort.Slice()能满足大部分的需求,同时减少了自己实现接口需要实现的Len和Swap两个方法,写法上也更加精炼。一个例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| package main
import (
"fmt"
"sort"
)
func main() {
people := []struct {
Name string
Age int
}{
{"Gopher", 7},
{"Alice", 55},
{"Vera", 24},
{"Bob", 75},
}
sort.Slice(people, func(i, j int) bool { return people[i].Name < people[j].Name })
fmt.Println("By name:", people)
sort.Slice(people, func(i, j int) bool { return people[i].Age > people[j].Age })
fmt.Println("By age:", people)
}
//Output
By name: [{Alice 55} {Bob 75} {Gopher 7} {Vera 24}]
By age: [{Bob 75} {Alice 55} {Vera 24} {Gopher 7}]
|
值得注意的一点是,这里的排序结果依赖于less函数的内容,并不是默认升序,如上述程序。
程序执行时间优化(20190816)
最近在刷PAT乙级的题,因为PAT考点一般只提供C/C++或Java环境的缘故,网上找到的90%都是C++代码,剩下的又绝大部分是Java,还有一小部分Python,其他语言还真没看到。我用go来刷题,遇到很多问题还真的只能自己慢慢琢磨,倒也很是能锻炼人。
在PAT乙级1015(德才论)和1018(锤子剪刀布)两题中,历经万难,总有测试点显示“运行超时”。仔细一想,不应该啊,go的编译执行速度应该算比较快了,比C++应该差不了多少,这也是go的优点,怎么就运行超时呢,前两天写的时候没想出来,就这么放下了,但这两天心里一直惦记着。知道今天,想到一件事,1015(德才论)还好说,涉及排序,可能算法不够好。1018(锤子剪刀布)一题中也没排序,这么就运行超时了,于是去网上找到了Python解法,竟然过了,彻底陷入了迷惘,go的速度连Python都比不过了吗,肯定有没注意到的地方,于是开始了执行时间优化之旅。
1018(锤子剪刀布)的原始代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| /*题目说明
大家应该都会玩“锤子剪刀布”的游戏,现给出两人的交锋记录,请统计双方的胜、平、负次数,并且给出双方分别出什么手势的胜算最大。
输入格式:
输入第 1 行给出正整数 N(≤10^5),即双方交锋的次数。随后 N 行,每行给出一次交锋的信息,即甲、乙双方同时给出的的手势。C 代表“锤子”、J 代表“剪刀”、B 代表“布”,第 1 个字母代表甲方,第 2 个代表乙方,中间有 1 个空格。
输出格式:
输出第 1、2 行分别给出甲、乙的胜、平、负次数,数字间以 1 个空格分隔。第 3 行给出两个字母,分别代表甲、乙获胜次数最多的手势,中间有 1 个空格。如果解不唯一,则输出按字母序最小的解。
输入样例:
10
C J
J B
C B
B B
B C
C C
C B
J B
B C
J J
输出样例:
5 3 2
2 3 5
B B
时间限制: 200 ms
内存限制: 64 MB
代码长度限制: 16 KB
*/
package main
import "fmt"
func findMax(a [3]int) int {
var max, index int
for k, v := range a {
if v > max {
max = v
index = k
}
}
return index
}
func main() {
var (
n int
jiawin, yiwin int
jia, yi [3]int
str = "BCJ"
)
fmt.Scanln(&n)
for i := 0; i < n; i++ {
var t [2]string
fmt.Scanln(&t[0],&t[1])
if t[0] == "B" && t[1] == "C" {
jia[0]++
} else if t[0] == "B" && t[1] == "J" {
yi[2]++
} else if t[0] == "C" && t[1] == "B" {
yi[0]++
} else if t[0] == "C" && t[1] == "J" {
jia[1]++
} else if t[0] == "J" && t[1] == "B" {
jia[2]++
} else if t[0] == "J" && t[1] == "C" {
yi[1]++
}
}
jiawin = jia[0] + jia[1] + jia[2]
yiwin = yi[0] + yi[1] + yi[2]
fmt.Println(jiawin, n-jiawin-yiwin, yiwin)
fmt.Println(yiwin, n-jiawin-yiwin, jiawin)
fmt.Printf("%c %c", str[findMax(jia)], str[findMax(yi)])
}
|
检查了半天实在找不到什么地方可以优化的,时间复杂度的大头是for循环,但能迁移出来的代码都已经迁移出来了,结果始终如下图
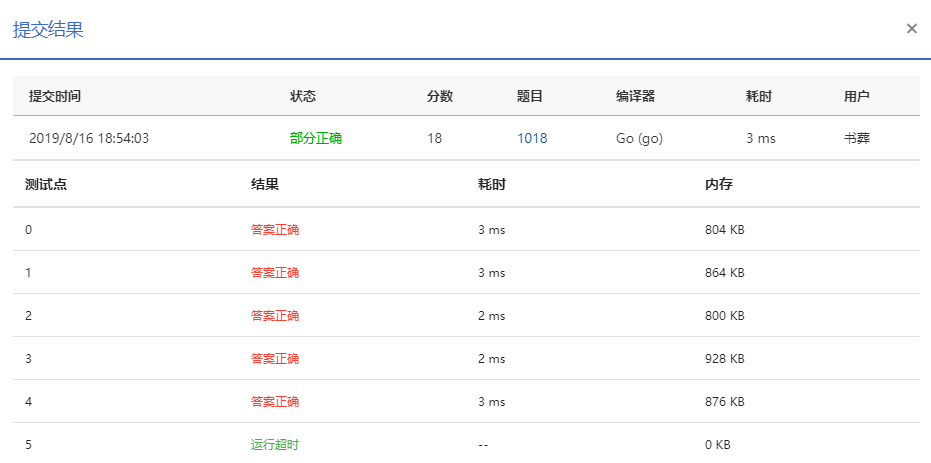
I/O性能
在google上搜go程序的执行时间怎么优化,最终在golang-nuts讨论组发现一个靠谱的问题以及有用的回答。
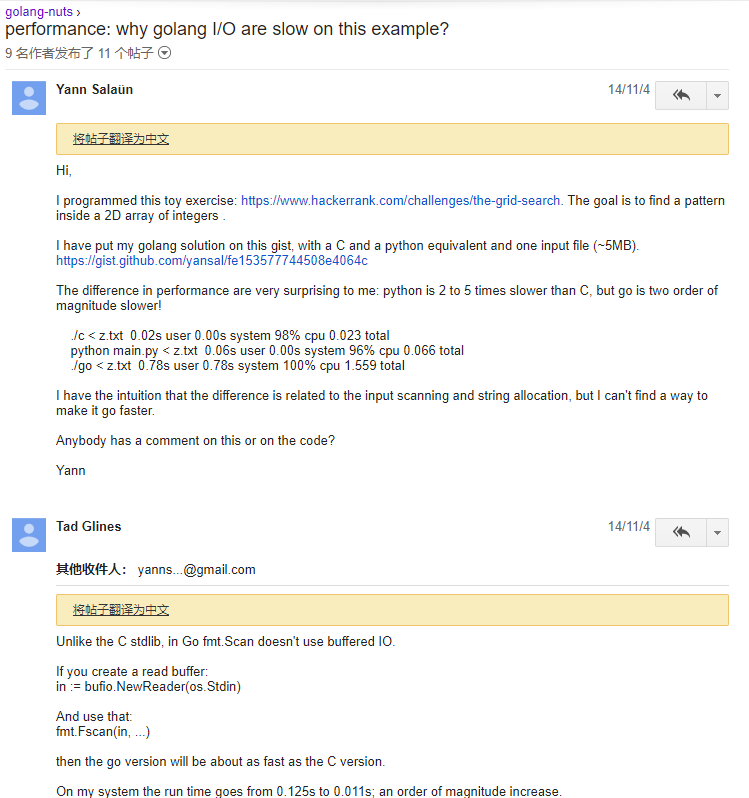
原来是I/O读写的问题,fmt包的读写这么不省心吗,怪不得,1015和1015如果测试点是边界值的话,循环要执行10000次,I/O读写出了问题,不超时才怪。看作者在之后的讨论中说他的程序“On my system: C runs in ~50ms, python in ~125ms and go in ~450ms.”也难怪Python都能通过,go通过不了了。
按照其他人的回答,使用bufio包替换了for循环中的fmt进行读取,改进的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| package main
import (
"bufio"
"fmt"
"os"
"strings"
)
func findMax(a [3]int) int {
var max, index int
for k, v := range a {
if v > max {
max = v
index = k
}
}
return index
}
func main() {
var (
n int
jiawin, yiwin int
jia, yi [3]int
str = "BCJ"
)
// 用fmt读取输入会有测试点超时
inputReader := bufio.NewReader(os.Stdin)
fmt.Scanln(&n)
for i := 0; i < n; i++ {
s, _ := inputReader.ReadString('\n')
t := strings.Fields(s)
if t[0] == "B" && t[1] == "C" {
jia[0]++
} else if t[0] == "B" && t[1] == "J" {
yi[2]++
} else if t[0] == "C" && t[1] == "B" {
yi[0]++
} else if t[0] == "C" && t[1] == "J" {
jia[1]++
} else if t[0] == "J" && t[1] == "B" {
jia[2]++
} else if t[0] == "J" && t[1] == "C" {
yi[1]++
}
}
jiawin = jia[0] + jia[1] + jia[2]
yiwin = yi[0] + yi[1] + yi[2]
fmt.Println(jiawin, n-jiawin-yiwin, yiwin)
fmt.Println(yiwin, n-jiawin-yiwin, jiawin)
fmt.Printf("%c %c", str[findMax(jia)], str[findMax(yi)])
}
|
果然通过了,如下图,最后一个测试点28ms,一想想题目时间限制是200ms,从超时到28,这提升,看起来1015的德才论一题也有救了。
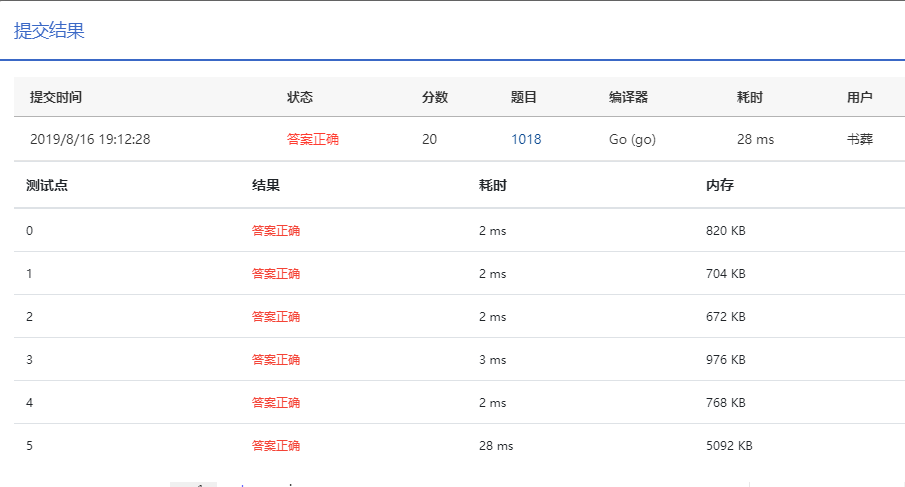
排序优化
1018德才论的原始代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
| /*
宋代史学家司马光在《资治通鉴》中有一段著名的“德才论”:“是故才德全尽谓之圣人,才德兼亡谓之愚人,德胜才谓之君子,才胜德谓之小人。凡取人之术,苟不得圣人,君子而与之,与其得小人,不若得愚人。”
现给出一批考生的德才分数,请根据司马光的理论给出录取排名。
输入格式:
输入第一行给出 3 个正整数,分别为:N(≤10^5),即考生总数;L(≥60),为录取最低分数线,即德分和才分均不低于 L 的考生才有资格被考虑录取;H(<100),为优先录取线——德分和才分均不低于此线的被定义为“才德全尽”,此类考生按德才总分从高到低排序;才分不到但德分到线的一类考生属于“德胜才”,也按总分排序,但排在第一类考生之后;德才分均低于 H,但是德分不低于才分的考生属于“才德兼亡”但尚有“德胜才”者,按总分排序,但排在第二类考生之后;其他达到最低线 L 的考生也按总分排序,但排在第三类考生之后。
随后 N 行,每行给出一位考生的信息,包括:准考证号 德分 才分,其中准考证号为 8 位整数,德才分为区间 [0, 100] 内的整数。数字间以空格分隔。
输出格式:
输出第一行首先给出达到最低分数线的考生人数 M,随后 M 行,每行按照输入格式输出一位考生的信息,考生按输入中说明的规则从高到低排序。当某类考生中有多人总分相同时,按其德分降序排列;若德分也并列,则按准考证号的升序输出。
输入样例:
14 60 80
10000001 64 90
10000002 90 60
10000011 85 80
10000003 85 80
10000004 80 85
10000005 82 77
10000006 83 76
10000007 90 78
10000008 75 79
10000009 59 90
10000010 88 45
10000012 80 100
10000013 90 99
10000014 66 60
输出样例:
12
10000013 90 99
10000012 80 100
10000003 85 80
10000011 85 80
10000004 80 85
10000007 90 78
10000006 83 76
10000005 82 77
10000002 90 60
10000014 66 60
10000008 75 79
10000001 64 90
时间限制: 400 ms
内存限制: 64 MB
代码长度限制: 16 KB
*/
package main
import (
"fmt"
)
//L is student level weight
const L = 100000000000000
//S is student grade weight
const S = 100000000000
//D is student id weight
const D = 100000000
func main() {
var (
n, l, h int
id, de, cai int
sum, level, count int
student []int64
)
fmt.Scanln(&n, &l, &h)
for i := 0; i < n; i++ {
fmt.Scanln(&id, &de, &cai)
if de >= l && cai >= l {
sum = de + cai
if de >= h && cai >= h {
level = 4
} else if de >= h && cai < h {
level = 3
} else if de < h && cai < h && de >= cai {
level = 2
} else {
level = 1
}
tmp := level*L + sum*S + de*D + D - id
student = append(student, int64(tmp))
count++
}
}
for i := 0; i < count; i++ {
for j := i; j < count; j++ {
if student[i] < student[j] {
tmp := student[i]
student[i] = student[j]
student[j] = tmp
}
}
}
fmt.Println(count)
for i := 0; i < count; i++ {
id = int(D - student[i]%D)
sum = int(student[i] % L / S)
de = int(student[i] % S / D)
cai = sum - de
fmt.Println(id, de, cai)
}
}
|
其实这已经是优化过了,之前写的时候用的正规的结构体的思路,为了优化,改成这种用权重的剑走偏锋的思路。但提交结果没有丝毫改变,超时就是超时。
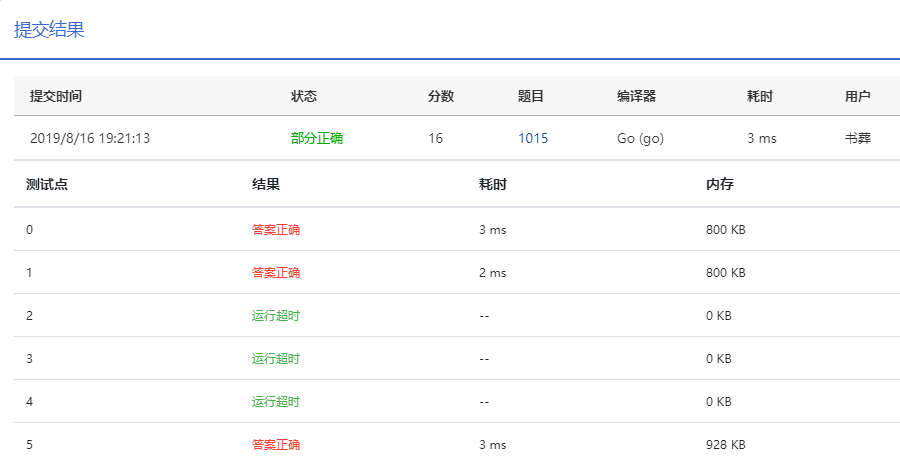
改呗,第一个for循环里的输入改成用缓冲区的bufio,按1018的提升幅度,估计可以。改进部分的代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| fmt.Scanln(&n, &l, &h)
inputReader := bufio.NewReader(os.Stdin)
for i := 0; i < n; i++ {
s, _ := inputReader.ReadString('\n')
t := strings.Fields(s)
id, _ = strconv.Atoi(string(t[0]))
de, _ = strconv.Atoi(string(t[1]))
cai, _ = strconv.Atoi(string(t[2]))
//fmt.Scanln(&id, &de, &cai)
if de >= l && cai >= l {
sum = de + cai
if de >= h && cai >= h {
level = 4
} else if de >= h && cai < h {
level = 3
} else if de < h && cai < h && de >= cai {
level = 2
} else {
level = 1
}
tmp := level*L + sum*S + de*D + D - id
student = append(student, int64(tmp))
count++
}
}
|
第2个测试点过了,但第3,第4个还是没过。
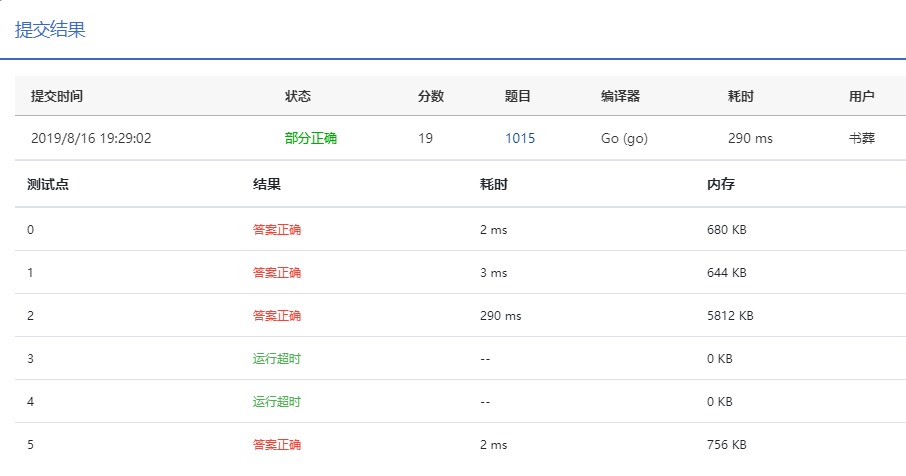
回去一看代码,得,最后一个for循环有输出,用fmt又费不少时间,继续改缓冲区,正巧这时候查到了GO语言基础进阶教程:bufio包,分析了bufio提升文件读写效率的原因,于是参考说明改了输出,如下:
1
2
3
4
5
6
7
8
9
10
| fmt.Println(count)
buf := bufio.NewWriter(os.Stdout)
for i := 0; i < count; i++ {
id = int(D - student[i]%D)
sum = int(student[i] % L / S)
de = int(student[i] % S / D)
cai = sum - de
buf.WriteString(fmt.Sprintf("%d %d %d\n", id, de, cai))
}
buf.Flush()
|
没怎么起作用,只是第2个测试点从290ms提升到了272ms。那就只能改排序了,程序里自己写了两层循环,本来以为能过,看来还是得用sort包。改进的完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| package main
import (
"bufio"
"fmt"
"os"
"sort"
"strconv"
"strings"
)
//L is student level weight
const L = 100000000000000
//S is student grade weight
const S = 100000000000
//D is student id weight
const D = 100000000
func main() {
var (
n, l, h int
id, de, cai int
sum, level, count int
student []int64
)
fmt.Scanln(&n, &l, &h)
inputReader := bufio.NewReader(os.Stdin)
for i := 0; i < n; i++ {
s, _ := inputReader.ReadString('\n')
t := strings.Fields(s)
id, _ = strconv.Atoi(string(t[0]))
de, _ = strconv.Atoi(string(t[1]))
cai, _ = strconv.Atoi(string(t[2]))
//fmt.Scanln(&id, &de, &cai)
if de >= l && cai >= l {
sum = de + cai
if de >= h && cai >= h {
level = 4
} else if de >= h && cai < h {
level = 3
} else if de < h && cai < h && de >= cai {
level = 2
} else {
level = 1
}
tmp := level*L + sum*S + de*D + D - id
student = append(student, int64(tmp))
count++
}
}
sort.SliceStable(student, func(i, j int) bool {
return student[i] > student[j]
})
fmt.Println(count)
buf := bufio.NewWriter(os.Stdout)
for i := 0; i < count; i++ {
id = int(D - student[i]%D)
sum = int(student[i] % L / S)
de = int(student[i] % S / D)
cai = sum - de
buf.WriteString(fmt.Sprintf("%d %d %d\n", id, de, cai))
}
buf.Flush()
}
|
这次终于通过了,第2个测试点竟然提升到了81ms,第3和第4个测试点也在200ms左右,没有卡在400ms的临界线,看起来还可以。

总结
- 涉及大量数据的读写时,利用bufio包通过缓冲区进行读写比fmt要快的多。
- 排序的代码可以调用sort包,不仅仅是自己写两层循环排序的问题,不是必要的情况下,同样的排序算法,自己写的很难说比得过封装好的。更何况,无论是哪种语言,调用的执行排序算法的包其实不是单纯执行快排或堆排序等比较快的排序算法,而是根据输入在调整的,所以不管为了时间性能还是写的方便,直接调用sort包完事儿。
bufio读取的字符串无法直接进行类型(20190827)
如下列代码,在使用bufio包中的ReadString读取字符串之后,这个字符串无法进行类型转换,每次使用strconv.Atoi()函数返回值均为0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| inputReader := bufio.NewReader(os.Stdin)
fmt.Println("Please input a number")
t, err := inputReader.ReadString('\n')
if err != nil {
fmt.Println("can't read number!")
}
fmt.Println("the number is", t)
if num, ok := strconv.Atoi(t); ok != nil {
fmt.Println("convert to int error", num)
}
//input
25
//output
Please input a number
the number is 25
convert to int error 0
|
因为这种写法其实经常遇到,之前编程的时候遇到这种情况没怎么注意,以为是算法问题,就换思路写了,直到这次只能用这种思路,才发现这里出现了问题。
Stackoverflow上相关的问题回答说这是因为ReadString读取字符串成功后会把'\n'一起加在字符串后面。查找包说明发现函数的原型和解释如下
1
2
3
| func (b *Reader) ReadString(delim byte) (string, error)
/* ReadString reads until the first occurrence of delim in the input, returning a string containing the data up to and including the delimiter. If ReadString encounters an error before finding a delimiter, it returns the data read before the error and the error itself (often io.EOF). ReadString returns err != nil if and only if the returned data does not end in delim. For simple uses, a Scanner may be more convenient.
*/
|
这种情况给出的建议是利用strings.Trim…系列去除末尾添加的字符,比如,对上面的错误程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| inputReader := bufio.NewReader(os.Stdin)
fmt.Println("Please input a number")
t, err := inputReader.ReadString('\n')
if err != nil {
fmt.Println("can't read number!")
}
fmt.Println("the number is", t)
t = strings.TrimRight(t, "\n")
if num, ok := strconv.Atoi(t); ok == nil {
fmt.Println("convert succeed", num)
}
//input
25
//output
Please input a number
the number is 25
convert succeed 25
|
 支付宝
支付宝 微信
微信