研究记录1-区块链的数据存储问题
区块链的本质是一个只增数据库,这就意味着其中存储的数据会随着时间的推移不断增加,而区块链分布式的特性要求节点需要存储区块链的整个副本,因此,区块链对节点存储能力的要求是越来越高的。
因此,我们首先来分析普通的电脑是否能应付区块链不断增长的体积,考虑最流行的比特币和以太坊两个平台。
1. 区块链的数据承载能力
以比特币和以太坊为例,但不考虑硬分叉产生的 Bitcoin Cash 和 Ethereum Classic,只考虑比特币和以太坊的主干,到 2019.01.11 15:06 为止,一些数据总结如下表,数据来源为 BitInfoCharts。
| Bitcoin | Ethereum | |
|---|---|---|
| Transactions last 24h | 319853 | 583335 |
| Transactions avg. per hour | 13327 | 24306 |
| Block Time(出块时间) | 9m 28s | 15.4s |
| Blocks Count | 558038 | 7046728 |
| Blocks last 24h | 151 | 5586 |
| Blocks avg. per hour | 6 | 233 |
| First Block | 2009-01-09 | 2015-07-30 |
| Blockchain Size | 232.51GB | 667.10GB |
首先,从总体上看。比特币发展十年链上数据共232.51GB,以太坊667.10GB,现有的存储介质,一台普通的电脑即可承受,但是,物联网设备是难以承受的。
从单位时间产生的数据量看区块链的承受能力,数据来源为 区块链浏览器。下面两个图分别展示了到 2019.01.11 15:36 为止 Bitcoin 和 Ethereum 最近的五个区块的情况,图中“大小(KB)”一栏右起第一个逗号实际上是小数点。比如第一个图(Bitcoin)中第一行数值中的1,162,094,实际上是1162.094KB;第二个图中第一行数值中的31,052,实际上是31.052KB
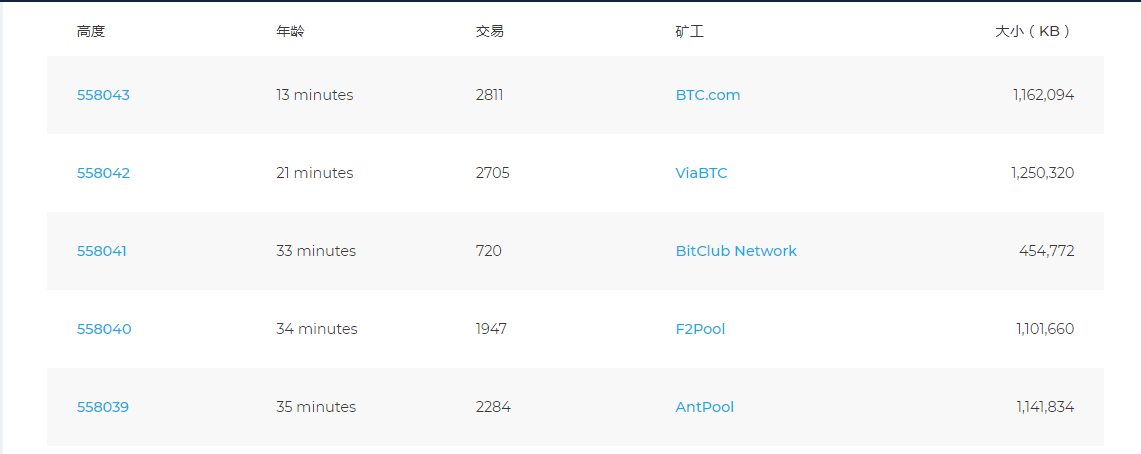
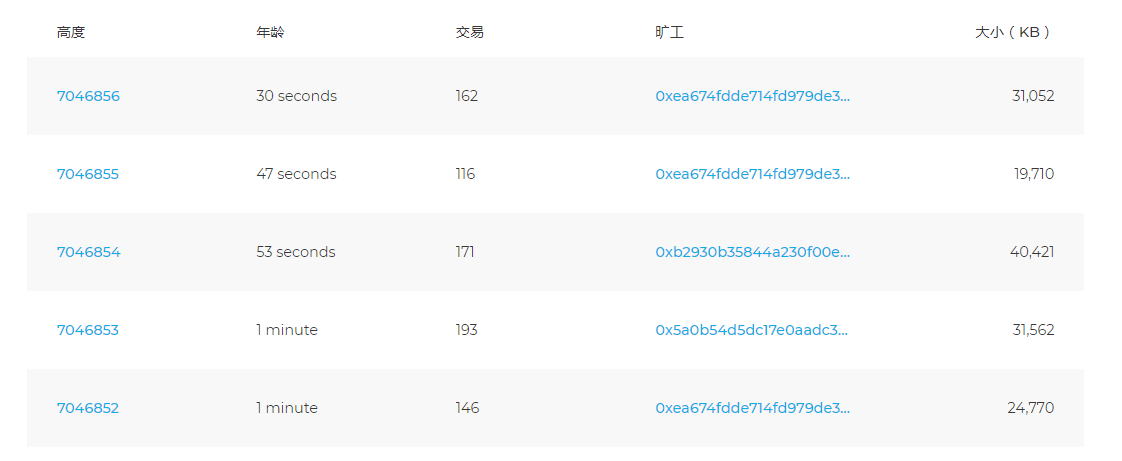
从已掌握的知识以及上面两个图可以看出,每个块中的交易数量是不定的,交易的大小也难以确定,所以数据量的大小我们以区块为最小单位。区块链出块的时间是受到控制的,但是具体到每个区块,出块时间都有不同,区块的大小也不同,而上面两个图中五个数据的样本较小,我们利用上面的表中的“平均每小时区块数”和下图中区块大小的历史变化做一定估计。下图数据来源为 BitInfoCharts,蓝色为比特币区块大小变化,红色为以太坊区块大小变化。

结合已掌握的知识,比特币控制区块大小在 1M 左右,当然,这么长时间的发展,比特币的区块扩容之路非常坎坷,并因此衍生出多条硬分叉。但此次我们只考虑 1M 限制的这种情况。另外,我们还简单的把整个区块的大小作为数据大小,不考虑区块头等固定结构的存在,这种情况下: $$ 比特币每秒处理的数据量 = \frac {平均每小时区块数 \times 区块大小}{3600} \approx 1.71KB $$ 而在以太坊中,理论上对交易大小或区块的大小都没有什么规定,不过这并不意味着交易携带的数据量大小没有上限,因为一个区块可以使用的 gas 是有上限的,叫做 gas limit。截至写这篇文章时,即 2019.01.11 16:40 为止,ethstats 显示的这个值为 8,000,029,约为 800万。因此,理论上,我们通过创建一个交易,让它消耗掉一个区块能用的全部 gas,就能得知一个交易理论上可以包含的最多数据。另外,决定数据大小的另一个因素是数据内容,因为不同的数据消耗的 gas 不同,具体的情况见 以太坊黄皮书 的附录G. Fee Schedule。为了便于计算,我们抽取如下几条:
- 4gas,paid for every zero byte of data or code for a transaction
- 68gas,paid for every non-zero byte of data or code for a transaction
- 21000,paid for every transaction
就假设没有非零字节数据了,这种情况下: $$ 一笔交易的最大数据量 = \frac {8000029-21000}{68 \times 1024} \approx 114.59KB $$ 同时,这大概也是一个区块的数据量上限。虽然实际环境下,根本达不到这么大(使用以太坊钱包Mist尝试过创建),而且在图2中也显示出了区块的大小基本都在 40KB 以下,但我们还是使用这个理论值做接下来的计算。和比特币的计算类似: $$ 以太坊每秒处理的数据量 = \frac {平均每小时区块数 \times 区块大小}{3600} \approx 177.81KB $$ 综上,以太坊平台下,预计物联网设备每秒产生的数据在 177.81KB 以下的话,可以直接将数据存在区块链中,而实际上,这个值已经是各种情况下的最优值了,正常运行能存的数据大小要比这个小的多。
在工业环境下我们经常考虑实时性问题,一开始我以为这实际上是数据量的问题,即使是非实时的数据采集,但当数据量足够大时,也和实时数据的情况无异。但现在明白,实时的含义就是即时的响应,这是区块链的延迟永远无法企及的,只能尽量提高。
2. 区块链存储数据的几种选择
考虑数据存储在区块链中时,我们先来考虑这样做是否是值得的,因为,区块链上存数据相比于传统数据库真的是昂贵的
首先考虑目前的去中心化存储的概况,来自 Wulf Kaal在Quora的回答
当前的区块链应用存储数据有如下几种选择:
- 把一切都存在区块链里
- P2P文件系统(Peer to peer file system),比如IPFS
- 去中心化的云文件存储,如Storj, Sia, Ethereum Swarm等
- 分布式数据库,如Apache Cassandra, Rethink DB等
- 巨链数据库 BigChainDB
- Ties DB
对每一种进行详细分析:
把一切都存在区块链里:最简单粗暴的解决方案。目前,大多数简单的去中心化应用程序都以这种方式工作。然而,这个方法有显著的缺点。首先,区块链交易确认缓慢。对于汇款来说,它似乎很快(每个人都可以等),但是,对于丰富的应用程序数据流来说,它实在是太慢了。因为丰富的应用程序每秒可能有数千次交易。其二,它是不可变的。不可变性是区块链的优势,它给了区块链高稳健性,但是对于数据存储来说却是个弱点。用户可能更改他们的个人资料或者更换照片,但先前的数据将会永远留在区块链中,任何人都能看到。这种不可变性造成了另外一个缺点,就是容量问题。如果所有的应用程序都将数据保存在区块链中,区块链的容量将会飞快增长,超过公开可用的硬盘容量大小。完整节点可能需要特殊硬件。它也许会导致区块链风险的集中化。这就是为什么在区块链中存储数据对于丰富的去中心化应用程序来说,不是个好选择。
P2P文件系统,如IPFS:IPFS 允许在客户端计算机上共享文件,并把它们整合到全局文件系统中。这个技术建立在 BitTorrent 协议和分布式哈希表(Distributed Hash Table)的基础之上。 它确实是对等的或点对点的,分享之前先存放到你自己的计算机上 。任何人只有在需要的时候才会去下载。它是内容可寻址的,因此不可能通过给定地址伪造内容。因为 BitTorrent 协议,才可以飞快地下载热门文件。但是,它也有一些缺点。如果你要分享文件,就得保持在线。至少在有人对你的文件感兴趣,想从你那里下载之前保持在线。它只提供静态文件,一旦上传,它们就不能被修改或删除。当然,你也不能通过其有意义的内容来搜索它们。
在IPFS中,数据被切分成block存储,通过散列表寻找块所在节点,但当数据内容小于1kb时,会直接和散列表放在一起上传给IPFS节点,不用额外再占用一个块。IIoT场景下,小数据量时,数据同样可以以交易形式直接寄存在区块链中。然而这个数据量的大小这个分界线如何判断是最关键的问题。
去中心化的云文件存储:还有一些去中心化云文件存储,它们去掉了 IPFS 的一些限制。从用户的角度来看,这些存储就是像 Dropbox 那样的云存储。区别在于内容是托管在用户的计算机上,而不是在数据中心里,这些用户出租硬盘空间而已。如今,有很多这样的项目。例如,Sia,Storj,Ethereum Swarm。你不再需要保持在线就能分享你的文件。只需上传文件,就可以在云中使用了。这些存储非常可靠,速度快,容量大。但是它们只提供静态文件,也没有内容搜索,还因为它们都是建立在租用的硬件上,所以不是免费的
分布式数据库:因为我们需要存储结构化的数据,并寻求高级查询能力,所以我们可以看一下分布式 noSql 数据库。为什么是 noSql 呢?因为有 CAP 定理的限制,严格的事物性 SQL 数据库不能真正地分布。为了让数据库分布,我们不得不要么牺牲一致性,要么牺牲可用性。NoSQL 数据库选择了可用性而不是一致性,代替一致性的是所谓“最终一致性”,即在网络中所有的数据库节点在一段时间之后会变得一致。这样的数据库有很多成熟的实现,如 MongoDB,Apache Cassandra,RethinkDB 等等。它们非常好——速度快、可扩展、容错、支持丰富的查询语言,但是对我们的应用程序来说有致命缺点。它们不是拜占庭证明(Byzantine-proof)。集群中的所有节点相互之间完全信任。因此,任何一个恶意节点就能毁掉整个数据库。
巨链数据库:另外一个名为巨链数据库的项目声称可以解决数据存储和交易速度问题。它也是区块链,拥有巨大的数据容量和非常快的交易。让我们看看它是怎么做到的。巨链数据库建立于 RethinkDB 集群之上。巨链数据库用它来存储所有的区块和交易。这是它显示出如此高的吞吐量的原因,它是基础 noSQL 数据库中的其中一个。所有的巨链数据库节点(用 BDB 表示)连接到集群,拥有对数据库的完全写访问权限。这里出现了一个问题,整个巨链数据库不是拜占庭证明的!任何恶意的 BDB 节点可以破坏 RethinkDB 集群。巨链数据库团队意识到这个问题,承诺将来会解决这个问题,然而它是这个架构的基石,要改动它几乎是不可能的。无论如何,巨链数据库可能对私有区块链很有用。但是,如果要避免混淆,它应该被叫做巨型私有区块链(BigPrivateBlockchain)。它不是公共存储的选项
Ties DB:这是目前好的公共数据库的可选项。最接近理想的是 noSQL 数据库。它们唯一缺乏的是拜占庭容错(Byzantine fault tolerance)。Ties.Network 数据库:ties.network 是对 Cassandra 数据库的深度修改,提供了一个更好的解决方案:TiesDB 继承了基础 noSQL 数据库的大部分功能,并增加了拜占庭容错和激励。有了这些功能,它可以成为公共数据库,并通过智能合约在 Ethereum 和其他区块链上启用功能丰富的应用程序。任何用户都有数据库写入权限。但是,用户由他们的公钥识别,同时,所有的请求有签名。创建之后,记录记住它的创建者,创建者则成为记录的所有者。之后,记录只能被记录所有者修改。每个人都可以阅读所有的记录,因为数据库是公开的。根据请求和复制检查所有的权限。额外的权限可以通过智能合约管理。
总的来讲,不论使用集中式的存储还是如上任何一种分布式的存储,都取决于应用场景。对于 IoT 数据来将,将数据完全存在区块链里是不值得的,同时也无法实现,理想的存储方式包括 Ties DB,去中心化的云文件存储(如Swarm),P2P文件系统(如IPFS)
当然,还有一篇 How Blockchain Data Storage Can Work for Enterprise Data Management 供参考
3. 论文中使用的存储方案
第二节提供了存储数据的几种选择,这一节我们总结一些论文中具体使用的方案和相应的原因。
| |
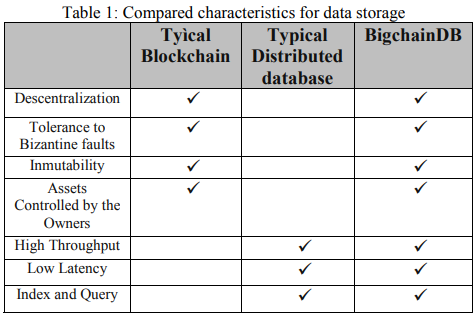
Román首先考虑了几种可选的经典存储方案,如 InfluxDB,MongoDB和MariaDB。这些方案面临像由数据库引擎本身不可用(关机,维护等)引起的数据丢失问题,同时,一个主要的限制是,这样一个系统中的查询需要共享对不同用户的访问权限,存储的数据能够轻易的暴露给攻击者。作者选用了 BigchainDB 作为存储方案,主要因为其结合了区块链和分布式数据库的优点,如下表:
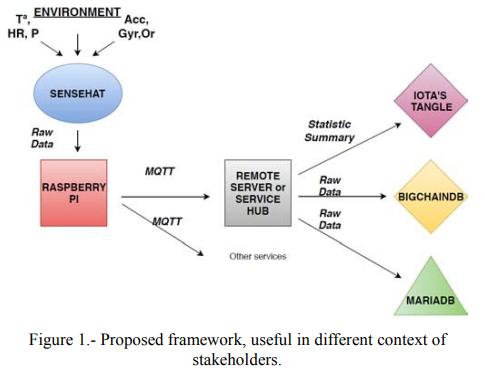
实际上,如下图,作者选用了不同的存储方案以适应不同的情况。如果数据旨在内部流通,则MariaDB足够;如果利益来自于产品价值链相关的不同组织,则使用BigchainDB;当商业模型中的利益需要公众参与,为了提供合适的透明度等级,应当使用完全公开的架构,即IOTA的Tangle。
| |
这篇使用IPFS。传统的云存储是中心化的系统,依赖于可信第三方来提供所有服务。在这样的中心化架构下,首先,云服务商可读、写和删除云中数据。其次,云存储中的数据可用性也存疑,虽然在多个云服务商那里存储数据可以增加数据可用性,但由于供应商锁定,需要大量的工作。
主要是对用户来讲,云服务商如何处理数据不是透明的,数据的完整性和可用性通常不包含在服务内容中,即使保证服务完整性,用户也难以验证,除非做一些额外的工作。只能信任云服务商显然是不利的。
文章提出了分布式存储方案EthDrive,并比较了它和云存储的时间性能,结果显示,当数据规格小于20MB时,分布式方案有更好的性能,当数据规格大于30MB时,云存储有更好的性能。
| |
依然是IPFS,云存储需要保证数据的机密性、完整性和可用性(CIA要求),虽然较为困难,但目前有方案通过加密机制保证数据的完整性。不过,当为不同平台提供动态物联网数据完整性服务时,这种方式缺乏灵活性。另外,我们只考虑了数据所有者需要验证它们在云中存储的数据的完整性的情况,但实际上,共享数据的数据消费者的需求在持续增加,而它们可能并不信任数据所有者所信任的云服务商。
该文提出的分布式数据完整性验证和传统的基于中心化云的完整性验证有如下优点:
- 更可靠,云无法单方面终止
- 随着客户端数量增加,数据完整性验证的效率得以增强
- 支持和数据消费者交易数据,并保证每笔交易的数据完整性
| |
使用SGS,由于物联网设备处理能力的限制,通常利用第三方服务商来做数据处理。由于用户将敏感的隐私数据传输给第三方服务商,用户被迫必须信任服务商实施了数据保护并提供了数据隐私保障。遗憾的是,服务商并没有这么做,它们经常违反数据隐私政策,使用从用户那里收集的数据用于未经授权的目的。服务商的这种不正当优势基于集中式架构,其中需要信任第三方系统作为中央权威来管理用户数据。为了消除服务提供商和用户之间数据访问策略执行中的这些不平衡,作者提出了一种基于区块链和智能合约的分布式数据管理系统。
论文使用了Inter的可信执行环境保存数据,其架构如下图:
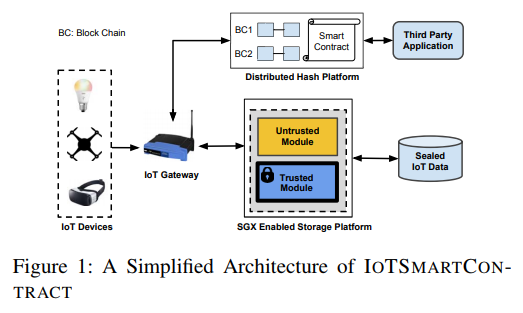
| |
以太坊的Swarm,使用Swarm主要是因为它是一个和以太坊集成的点对点存储方案,它承诺零停机时间,并且具有DDOS抗性,容错性和抗审查性。它是一种类似torrent的服务,内置激励措施,可以保证由于与以太网网络层的高度耦合而导致上传的数据持久性。因此,它是针对物联网的存储服务的强有力候选者
| |
使用传统的云存储。云服务通过以低成本为大型网络提供高处理能力,无限存储容量和高可扩展性来增强物联网设备。此外,云为底层异构物联网网络提供有效的管理服务,同时为利用物联网设备产生的数据的应用提供高效灵活的中间层。
云存储可以轻松访问从位于网络不同位置的大量物联网设备收集的数据。因此,使云应用或第三方能够更有效地分析数据以便做出决策。
完整梳理
Multichain 虽然针对的是金融领域,但是在 2.0 中推出了一种称之为 off-chain 的结构用来存储大量的数据,减轻区块链负担,在这一特性的描述中,Multichain 对区块链数据存储问题给出了一个非常棒的总结。
文章地址:https://www.multichain.com/blog/2018/06/scaling-blockchains-off-chain-data/
 支付宝
支付宝 微信
微信